Authors: Anupama Jha, Joseph K. Aicher, Deependra Singh and Yoseph Barash
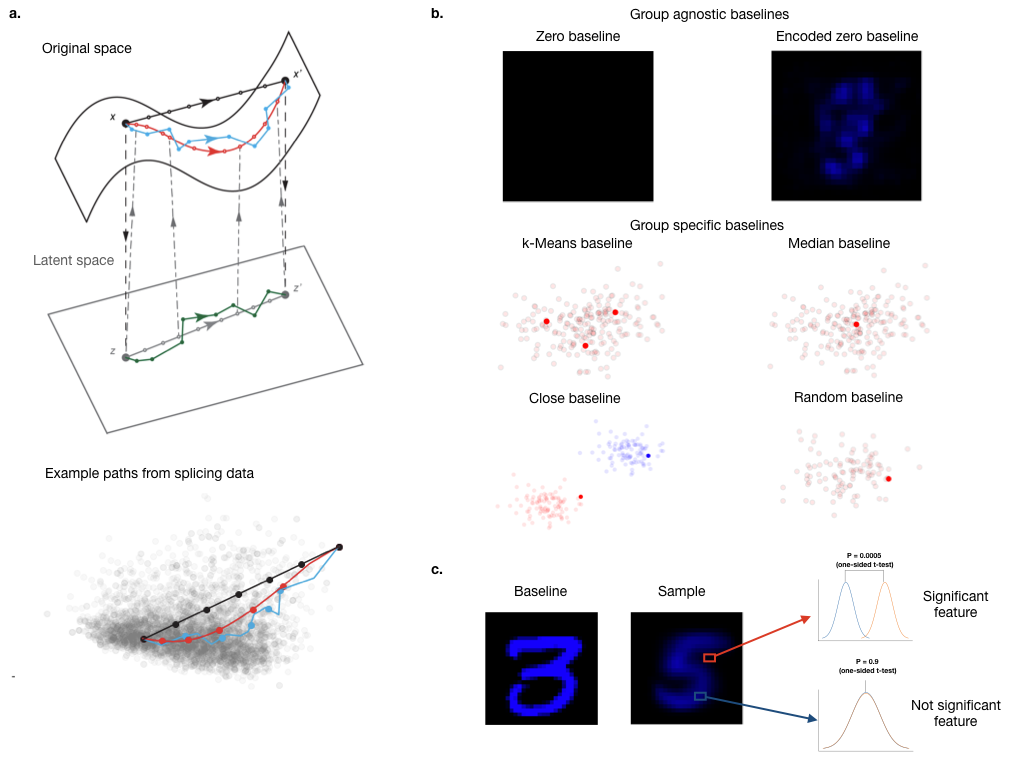
Despite the success and fast adaptation of deep learning models in a wide range of fields, lack of interpretability remains an issue, especially in biomedical domains. A recent promising method to address this limitation is Integrated Gradients (IG), which identifies features associated with a prediction by traversing a linear path from a baseline to a sample. We extend IG with nonlinear paths, embedding in latent space, alternative baselines, and a framework to identify important features which make it suitable for interpretation of deep models for genomics.
Supplementary materials are available here. This webpage will serve as the gateway for additional figures, data, and code following publication.